Network Performance Comparsion for HighPACE and
Grendel
The performance of the communications interconnect was tested for two
Beowulf type systems. The first system, known as Grendel, was constructed
in the fall of 1998 at PSU. It is composed of 16 dual Pentium II 400 MHz
computers. Each computer, or node, contains 512 MB of memory, an IDE hard
drive, and a fast ethernet adapter. Each node is connected to a port in
a fast ethernet switch. Linux kernel 2.2.13 is used on each node along
with MPICH 1.2.0.
The second system, known as HighPACE, was constructed in the spring
of 2000 at PSU. It is composed of 16 dual Pentium III 450 MHz computers.
Each node contains 512 MB of memory, an IDE hard drive, and a Myrinet adapter
in a 64-bit PCI slot. Each node is connected to a port in a 16-way Myrinet
switch. Linux kernel 2.2.13 is used on each node along with GM-1.2pre12
and MPICH-over-GM 1.1.2.13.
The one way bandwidth and latency were measured for both Grendel and
HighPACE. This tests the performance of two processes communicating directly
though the network.
Measurements were taken with version 2.3 of the Netpipe program [1].
Netpipe uses a standard Ping-Pong test that is repeated many times and
the average results are reported. These tests were made through the TCP
interface as well as through the MPI interface on both machines. Figures
1-4 show bandwidth for both interfaces on both computing systems. It is
clear that the peak bandwidth provided by the Myrinet interconnect on HighPACE
is more than triple that provided by the fast ethernet used by Grendel.
This is true for both the MPI and TCP interfaces.
Figure 5 show the latency for different interfaces on each machine.
In this case, the latency is a measure of the time required to send a very
short message (less than one byte). The bulk of this time is composed of
message startup overhead. It is clear that the MPI interface for Myrinet
provides a latency that is almost an order of magnitude smaller than those
seen for any interface using fast ethernet. Codes that are based on fine-grained
parallel algorithms, which tend to send many short messages, will benefit
the most when using this low latency interface. It should be noted that
the TCP interface for Myrinet requires the program to go through the kernel
in order to access the TCP driver. A significant amount of overhead is
associated with converting from user to system space when a driver is accessed
through the kernel. However, the Myrinet MPI interface runs on top of the
Myrinet message-passing program, GM. GM allows the user program to directly
access the network card from user space and thereby eliminates the overhead
incurred when going through the kernel.
The throughout was measured for both Grendel and HighPACE for two types
parallel MPI operations. This tests the performance of the system when
several processes need to communicate information in parallel using MPI.
These tests were run on various numbers of processors in order to gauge
the effect of parallel network traffic on the performance of the communications
system. All tests were performed using version 2.2 of the Pallas MPI Benchmarks
software [2].
The first test is called the Sendrecv test. This test is composed of
a periodic communication chain. Each process sends to the right and receives
from the left neighbor in the chain. Figures 6-7 show the throughput for
Grendel and HighPACE for the Sendrecv test. The peak throughput for the
Myrinet based HighPACE is more than three times higher than that of the
fast ethernet based Grendel. This is true for the range of parallel processes
from 4 to maximum of 32. Also, HighPACE is able to maintain nearly the
same peak throughput as the number of processes increases. The peak throughput
for Grendel decreases as the number of processes increases. Both machines
exhibit a noticeable decline in throughput when going from 16 to 32 processes.
This is a result of having two processes running on each node. Recall that
both machines are composed of 16 dual processor computers. When 16 processes
are running, each has dedicated access to the network interface adapter.
However, when 32 processes are running, each process must share access
to the network interface with the other process. This sharing effectively
reduces the bandwidth available to each process.
The second test is called the Exchange test. This test mimics the types
of communications patterns often occurs in grid splitting algorithms (boundary
exchanges). Each process exchanges data with both the left and right neighbors.
Figures 8-9 show the throughput for Grendel and HighPACE for the Exchange
test. The peak throughput for HighPACE is almost three times higher than
that of Grendel. This is true for the range of parallel processes from
4 to maximum of 32. As seen in the Sendrecv test, a sharp drop-off in throughput
when going from 16 to 32 processes is apparent. Again, this is due to having
two processes on running on each node.
Also, it should be noted that both machines show a decrease in throughput
as the message sizes increase above 10KB when using MPI. This could be
related to the MPICH library and is a topic of further research.
In conclusion, the communications interconnect was tested and compared
for two Beowulf class parallel computers. It was found that MPI interface
for HighPACE exhibits low latency and high bandwidth compared to TCP/MPI
interfaces for fast ethernet. Such features are critical for obtaining
high performance with codes based on fine-grained parallel algorithms.
REFERENCES
[1] ftp://ftp.scl.ameslab.gov/pub/netpipe/
[2] http://www.pallas.de
or http://www.pallas.de/pages/pmbd.htm
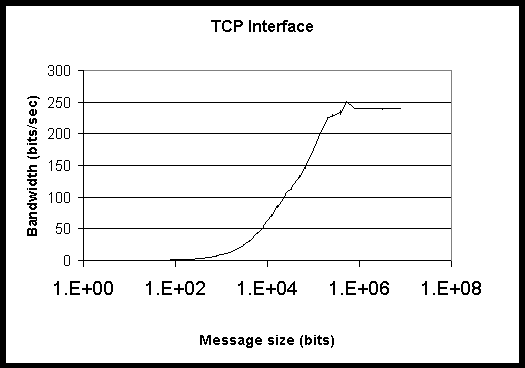
Figure 1: Bandwidth for HighPACE for Ping-Pong test through TCP interface
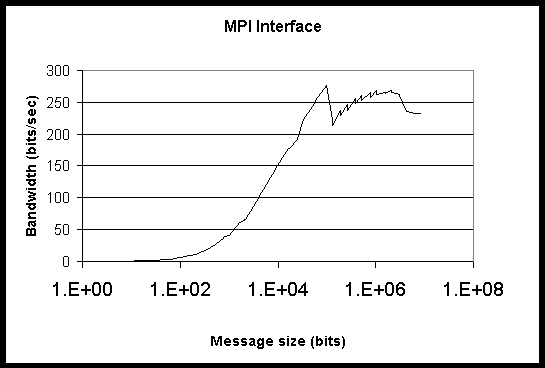
Figure 2: Bandwidth for HighPACE for Ping-Pong test through MPI interface
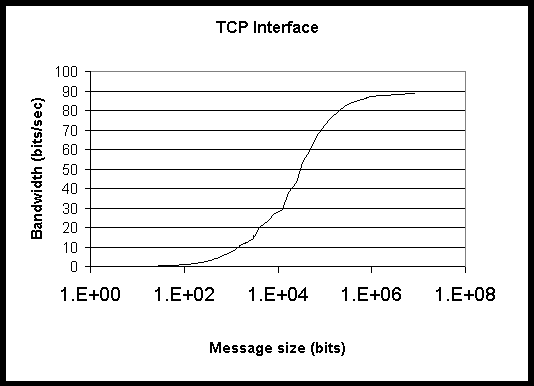
Figure 3: Bandwidth for Grendel for Ping-Pong test through TCP interface
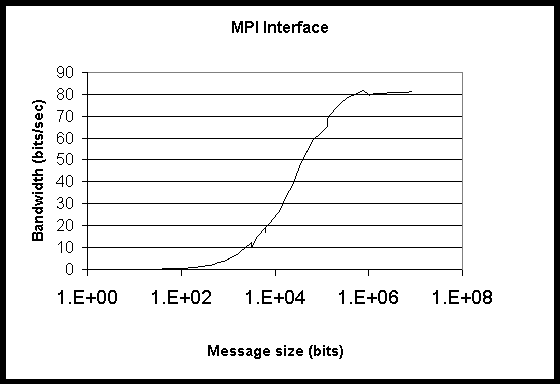
Figure 4: Bandwidth for Grendel for Ping-Pong test through TCP interface
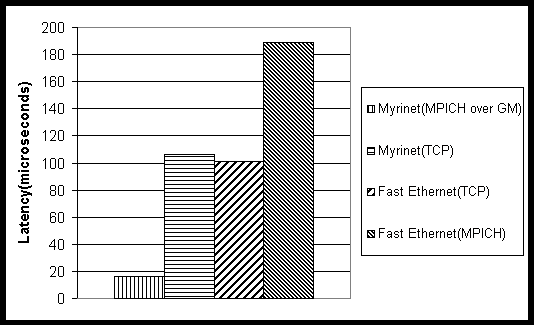
Figure 5: Comparison of latency for various interfaces
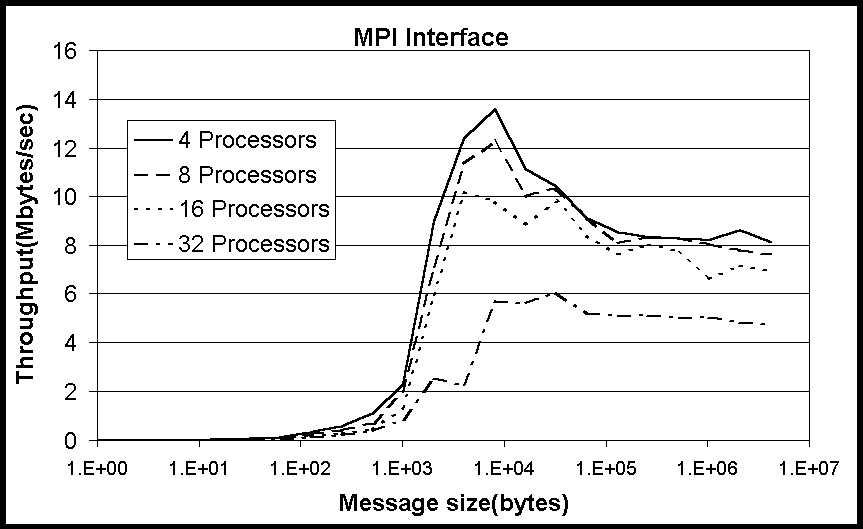
Figure 6: Throughput for Sendrecv test on Grendel for various numbers
of processors
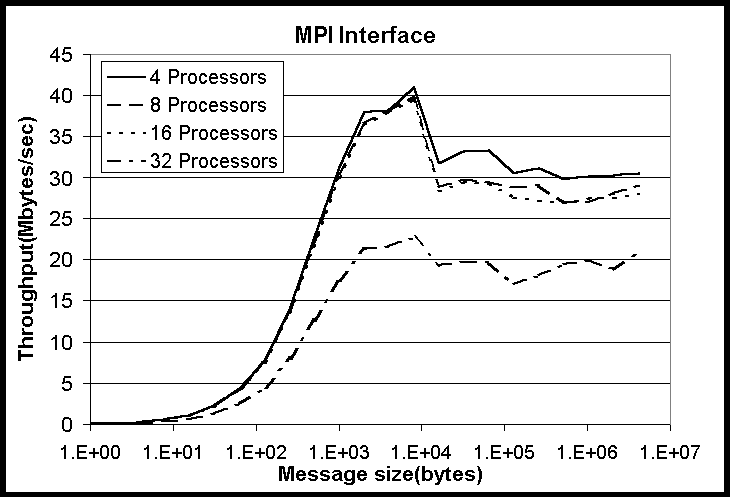
Figure 7: Throughput for Sendrecv test on HighPACE for various numbers
of processors
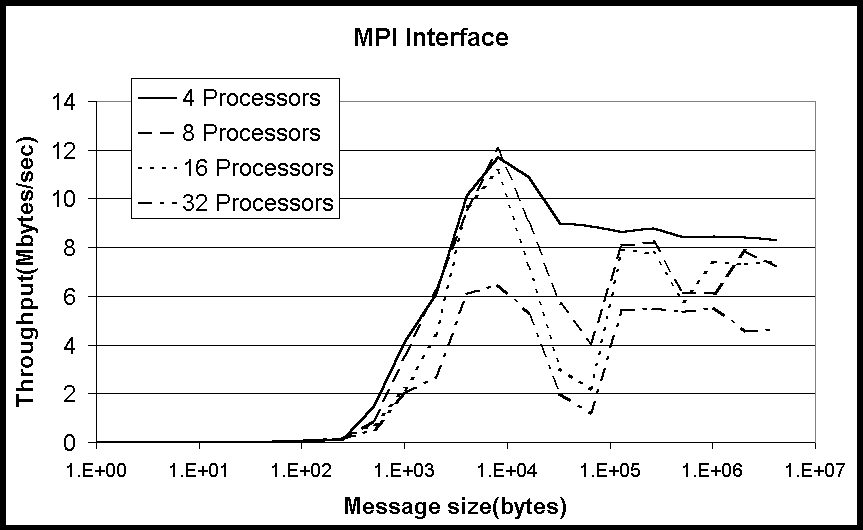
Figure 8: Throughput for Exchange test on Grendel for various numbers
of processors
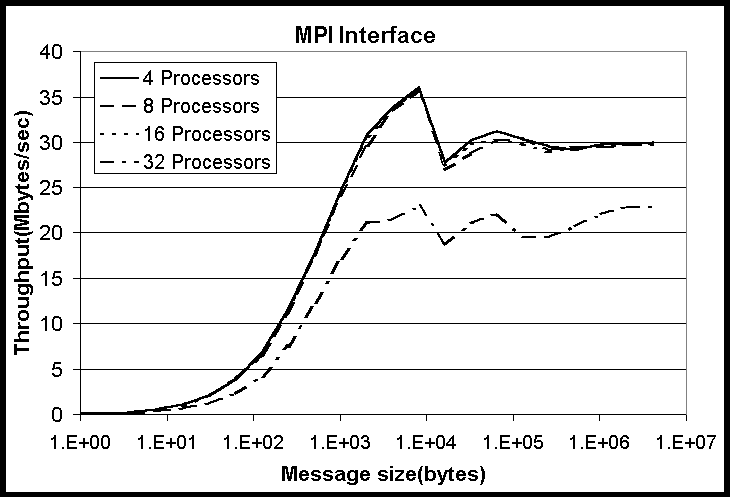
Figure 9: Throughput for Exchange test on HighPACE for various numbers
of processors